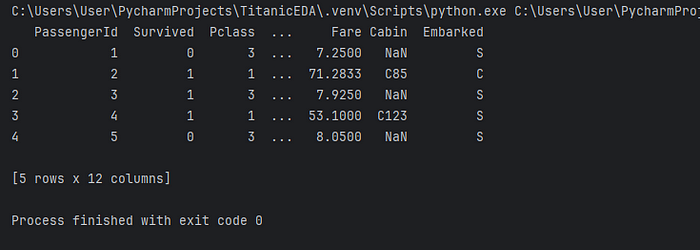
APIs 和網頁爬蟲讓我們能夠收集現實世界的數據進行分析。在這篇文章中,我希望談論一下基礎知識,
- 使用 API 來獲取數據
- 使用 BeautifulSoup 進行網頁爬取
使用 API 來獲取數據
API(應用程式介面)是一組規則和協議,允許不同的軟體應用程式相互通信。它充當橋樑,使一個系統能夠從另一個系統請求數據或服務,而無需了解其內部運作。例如,當您使用天氣應用程式時,它會從天氣提供者的 API 獲取即時數據,而不是自行存儲所有天氣數據。API 在數據分析中至關重要,因為它們允許分析師從各種來源訪問、檢索和整合即時或大規模數據,而無需手動下載。
在我們最初的文章中,我們總是通過手動從網站下載或創建自己的數據集來處理 Excel 表格或 csv 文件。隨著我們不斷進步並開始處理大型數據集,這可能會變得有些不切實際。這就是為什麼我們使用 API 的原因。此外,手動下載的文件可能無法存儲實時或最新的數據。許多 API 提供最新或實時數據,這對於金融、天氣、股票市場或交通分析至關重要。API 還允許您高效地處理大型數據集,而無需將其存儲在本地。讓我們來看看數據分析中的一些 API,
- 財務數據:Alpha Vantage API、Yahoo Finance API 用於股票市場分析
- 社交媒體數據:用於情感分析的 Twitter API
- 太空數據:NASA 用於太空任務數據的 API
- 天氣數據:OpenWeather API 用於氣候研究
現在我們知道了為什麼需要 API,讓我們來看看如何獲取數據並用於分析。大多數網站提供 API 來訪問結構化數據。在本文中,我們將使用 requests 庫來進行 API 請求。
pip install requests我們現在要從一個公共 API(JSONPlaceholder API,這是一個免費的測試 API)中獲取數據。
import requests
url = "https://jsonplaceholder.typicode.com/users"
response = requests.get(url) #fetch data
if response.status_code == 200:
data = response.json() # Convert response to JSON format
print(data[:2]) # Show first 2 users
else:
print("Error:", response.status_code)讓我們逐行查看這段代碼。
- requests.get() 用於從網址獲取數據
- status_code==200 是在檢查數據獲取是否成功。其他常見的狀態碼包括 404 表示未找到,以及 500 表示伺服器錯誤。
- response.json() 將數據轉換為 JSON 格式。
當你發出一個 API 請求時,回應通常是以 JSON 格式(JavaScript Object Notation)返回,這是一種輕量級的數據格式,易於閱讀和傳輸。然而,回應本身只是一個字串。.json()方法用於將這個字串解析為 Python 字典,使數據更易於處理。
讓我們來看一下輸出。

一些 API 需要 API 金鑰才能訪問。在這種情況下,你需要解析 API 金鑰來訪問數據。例如,從 OpenWeather API 獲取天氣數據。
api_key = "your_api_key_here" # Replace with your actual API key
city = "London"
url = f"http://api.openweathermap.org/data/2.5/weather?q={city}&appid={api_key}"
response = requests.get(url)
data = response.json()
print(data)永遠記得保護好 API 金鑰,切勿在公開儲存庫中暴露它們。
使用 BeautifulSoup 進行網頁抓取
如果沒有可用的 API,我們可以從網頁中抓取數據。網路爬蟲是使用代碼自動從網站提取數據的過程。它涉及獲取網頁、解析其內容並提取有用信息。這可以使用 Python 中的 BeautifulSoup、Scrapy 和 Selenium 等工具來完成。網路爬蟲對於數據分析至關重要,因為它允許你從網路上收集大量可能無法通過 API 或數據庫獲得的數據。在本文中,我們將討論 BeautifulSoup。
BeautifulSoup 是一個用於解析和提取 HTML 和 XML 文件數據的 Python 函式庫。它常用於網頁爬蟲中,以分析網頁內容並提取有用的資訊。
lxml 是另一個用於處理 XML 和 HTML 的高效能函式庫。在處理大型 HTML 頁面時,它比 BeautifulSoup 更快。
首先讓我們安裝兩個庫 BeautifulSoup 和 lxml。
pip install beautifulsoup4 lxml現在讓我們試著使用這些庫來抓取一些數據。在這篇文章中,我將從一個維基百科頁面抓取標題。
from bs4 import BeautifulSoup
import requests
import lxml
url = "https://en.wikipedia.org/wiki/Web_scraping"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml") # Parse HTML
headings = soup.find_all("h2")
for h in headings:
print(h.text.strip())- soup.find_all(“h2”) 找到所有的 <h2> 標籤
- text.strip() 將提取並清理數據
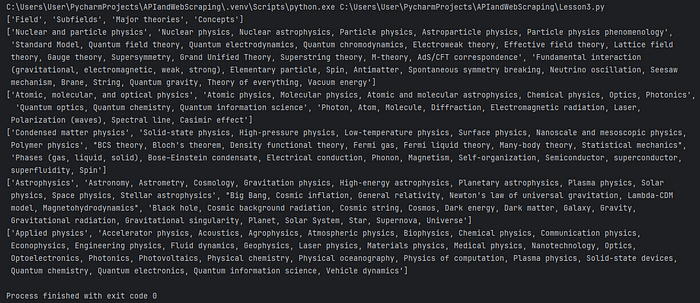
許多網站都有表格數據,例如股票價格。讓我們來看看如何從維基百科中抓取表格數據。
from bs4 import BeautifulSoup
import requests
import lxml
url = "https://en.wikipedia.org/wiki/Physics"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
# Find the first table on the page
table = soup.find("table", {"class": "wikitable"})
# Extract rows
rows = table.find_all("tr")
# Loop through rows & extract data
for row in rows:
cells = row.find_all(["th", "td"]) # Get table headers & data cells
print([cell.text.strip() for cell in cells])如果你正在解析的 URL 包含任何表格,那麼這將會抓取頁面上的第一個表格。
現在你可能在想,我們是否可以在任何網站上使用網頁爬蟲?
答案是否定的。網頁爬取伴隨著法律和道德考量。你不能未經檢查網站政策就隨意爬取任何網站。那麼,你如何辨別是否允許網頁爬取呢?
- 檢查網站的 robots.txt 文件(https://wikipedia.org/robots.txt)以查看是否允許爬取。
- 閱讀服務條款並尋找有關數據使用的規則。
- 你沒有損害網站,沒有讓其伺服器超載,也沒有違反其服務條款。
- 如果網站有 API,這是首選的方法。
- 在請求之間使用延遲以避免伺服器過載。在請求之間使用“time.sleep(1)”。
總而言之,
- 如果存在 API,那麼務必使用它。
- 如果沒有 API 存在,那麼網頁抓取就是解決之道。但你不能從任何網站抓取數據。只使用允許網頁抓取的網站。
- 檢查網站的 robots.txt 文件
- 檢查網站的使用條款
- 即使允許網頁爬取,也要注意道德考量。不要讓網站過載,在請求之間使用 time.sleep(1)