
在工作中,我們編寫的程式碼盡可能地易於人類閱讀。這意味著以下(非詳盡的)列表:
- 變數名稱具有意義且較長(而非使用 a、b 和 c)
- 函數名稱具有意義且較長
- 大量的評論和文件解釋代碼
- 類型提示無處不在
- 字串似乎更長且更冗長
- 等等等等
這意味著代碼風格將不可避免地演變以適應上述情況。
因此,以下是我在過去幾年的工作中學到的一些生產級 Python 代碼風格。
1) 使用括號進行元組解包
這是一些普通的元組解包:

在生產級別的程式碼中,我們通常不會使用像 a 或 b 這樣的變數名稱——相反,我們的變數名稱會更長且更具描述性。
因此,我們可能會使用括號來幫助元組解包,像這樣:

注意到這樣一來,我們的元組解包可以容納更長(且更具描述性)的變數名稱
一個更現實的例子:

2) 多行列表推導式
以下是普通列表推導式的樣子:

在生產代碼中,我們通常不使用變量名 i——我們的變量通常更長且更具描述性,以至於我們無法將整個列表推導式塞進一行代碼中。
我會如何重寫上述代碼:

一個更現實的例子:

3) 使用括號組合字串
生產級的字串通常由於其冗長而無法放入一行中。因此,我們使用括號將它們組合起來。
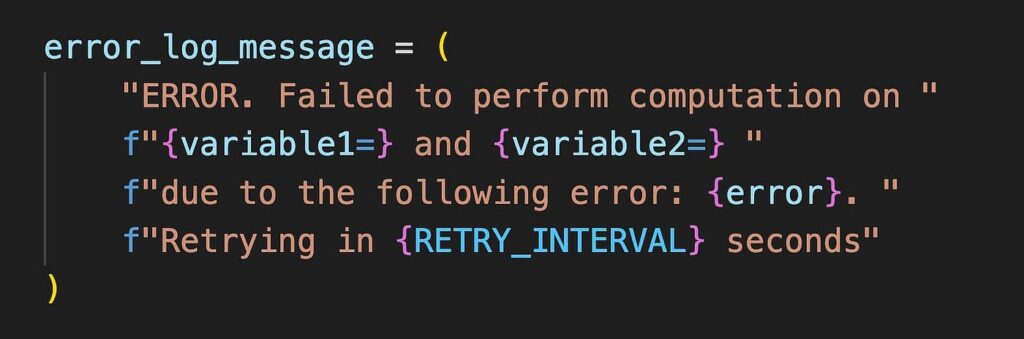
注意 — 在括號內,使用引號的字串字面值會自動合併,我們不需要使用 + 運算子來實現這一點
4) 使用括號輔助的多行方法鏈接
正常的方法鏈接:

在生產級別的程式碼中,方法名稱大多數時候會更長,並且我們會將更多的方法鏈接在一起。
再次,我們使用括號將所有這些內容放入多行中,而不是縮短任何方法名稱或變數名稱。
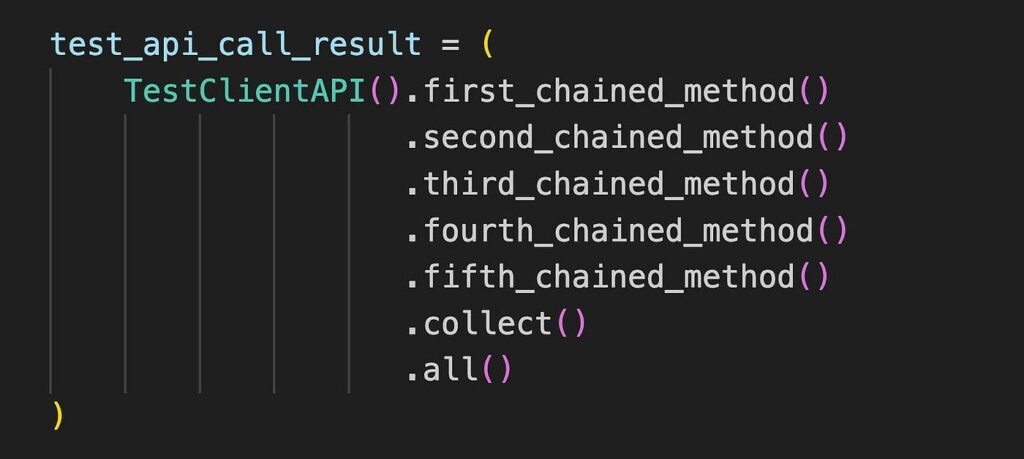
請注意,如果我們在括號內進行方法鏈接,則不需要使用 \ 字符來進行明確的換行
5) 索引嵌套字典
正常索引嵌套字典的方式:
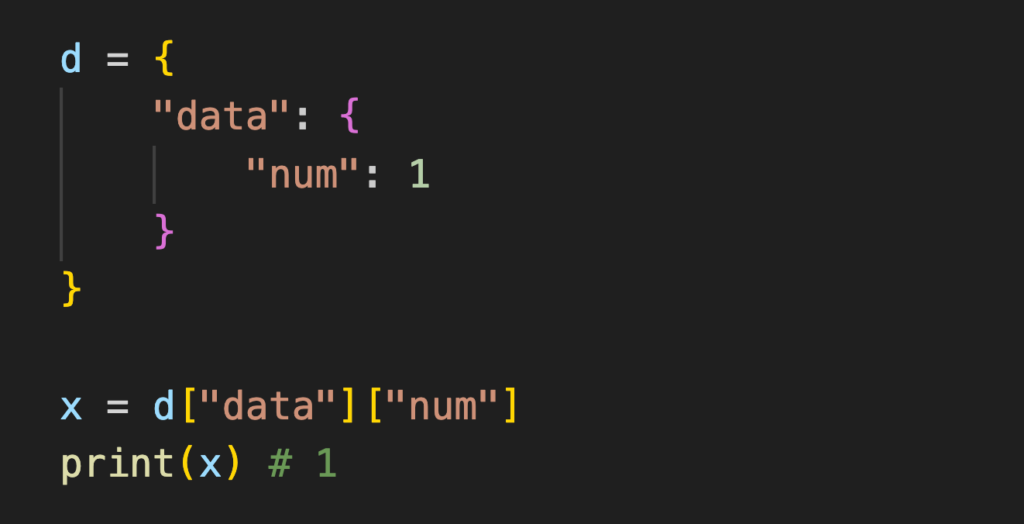
這裡有一些問題:
- 生產級代碼中的字典有更多層次的嵌套
- 字典鍵的名稱變得更長了
- 我們通常無法將整個嵌套索引代碼壓縮成一行。
因此,我們將其拆分為多行,如下所示:
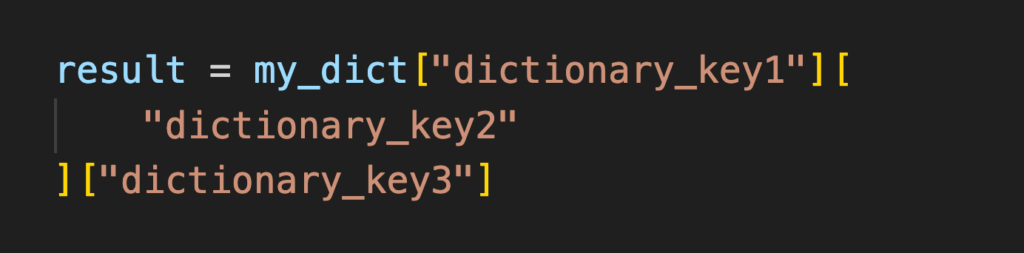
如果這還不夠,我們將索引代碼拆分為更多行:
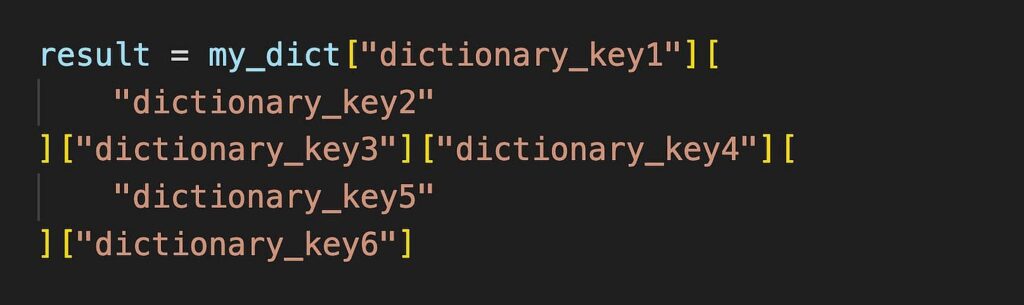
或者如果我們仍然覺得這難以閱讀,我們可以這樣做:

6) 撰寫易讀且資訊豐富的函數
我們學生時代如何撰寫函式:

包含此類代碼的 PR 很可能會被拒絕
- 函數名稱不具有描述性
- 參數變數名稱不佳
- 沒有類型提示,所以我們第一眼無法知道每個參數應該是什麼數據類型
- 沒有類型提示,所以我們也不知道我們的函數應該返回什麼
- 沒有文件字串,所以我們必須推斷我們函數的功能
以下是我們在生產級 Python 代碼中編寫函數的方式
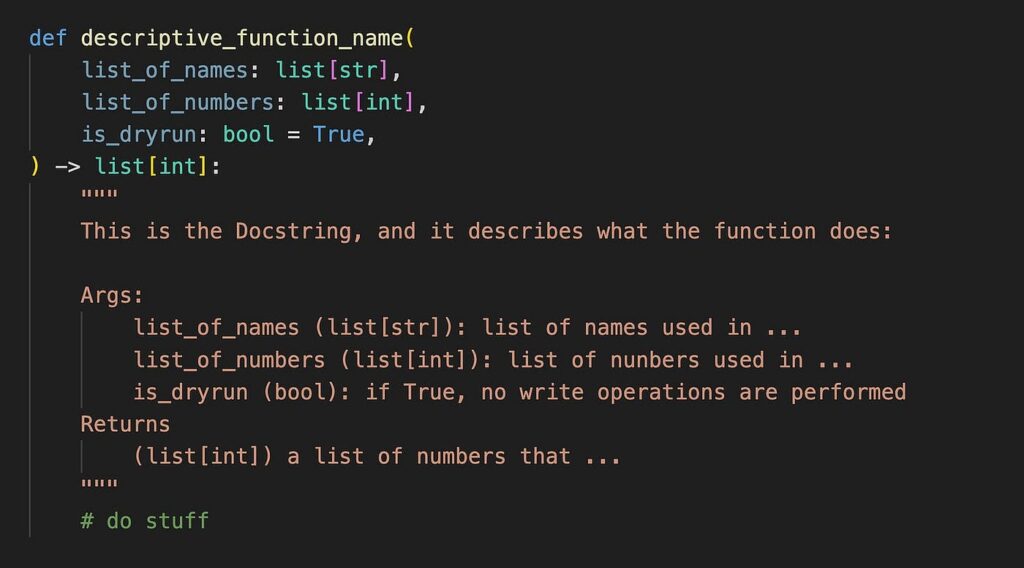
- 函數名稱應具有描述性
- 參數名稱應該更具描述性,而不是例如 a, b, c
- 每個參數都應該有類型提示
- 函數的返回類型也應包括在內
- 一個詳細描述函數功能、接收參數及其輸出的文檔字符串應作為三引號內的字符串包含。
7) 盡可能減少縮排層級
這是一個 for 迴圈。如果我們的條件被滿足,我們就做某事。

一些同事和高級工程師可能會對這段代碼吹毛求疵 — 它可以通過減少縮進層次來寫得更好。
讓我們重寫這個,同時減少 do_something() 的縮進層級

注意到,僅僅通過使用 `if not condition` 而不是 `if condition`,`do_something()` 的縮進級別就減少了 1 級。
在生產級別的程式碼中,可能會有更多的縮排層次,而如果層次太多,我們的程式碼就會變得令人煩躁且難以閱讀。因此,這個技巧讓我們能夠使程式碼稍微整潔一些,更易於人類閱讀,
8) 帶有括號的布林條件
這是一個使用 and 關鍵字連接三個條件的 if 語句。

在生產級別的代碼中,條件變得更長,且可能會有更多的條件。因此,我們可以通過將這個龐大的條件重構為一個函數來解決這個問題。
或者如果我們判斷沒有必要僅僅為此編寫一個新函數,我們可以使用括號來編寫我們的條件語句。

這樣一來,我們就不必為了這一個條件語句而被迫編寫新的函數或變量,同時我們還能保持代碼的整潔和可讀性。
有時候我可能真的更喜歡這樣寫,不過這只是基於個人偏好:

9) 防止 None 值
正常代碼,訪問對象的某些嵌套屬性。

這段代碼存在一些可能導致我們的 PR 被拒絕的問題:
- 如果 dog 是 None,我們會得到一個錯誤
- 如果 dog.owner 是 None,我們也會得到一個錯誤
- 基本上,這段程式碼並未防止 `dog` 或 `dog.owner` 可能為 `None` 的情況。
在生產級代碼中,我們需要積極防範此類情況。以下是我如何重寫這段代碼的方式。

Python 中的 and 和 or 運算符是短路運算符,這意味著一旦它們得到明確的答案,就會停止評估整個表達式。
- 如果 dog 是 None,我們的表達式在 “if dog” 處終止
- 如果 dog 不是 None,但 dog.owner 是 None,我們的表達式會在 “if dog and dog.owner” 處終止
- 如果我們沒有任何 None 值,dog.owner.name 會成功被存取,並用於與字串 “bob” 進行比較
這樣一來,我們就能額外防範狗或狗主人可能為 None 值的情況。
10) 防止遍歷 None 值
這是我們如何遍歷某些可迭代對象(例如列表、字典、元組等)的方式

這個問題的一個缺點是它無法防止 mylist 為 None——如果 mylist 恰好是 None,我們會得到一個錯誤,因為無法遍歷 None。
以下是我如何改進這段程式碼的方式:

表達式“mylist or None”
- 如果 mylist 為真值(例如非空可迭代對象),則返回 mylist
- 如果 mylist 為假值(例如 None 或空的可迭代對象),則返回[]
因此,如果 mylist 為 None,表達式“mylist or None”會返回[],這樣我們就不會遇到不想要的異常。
11) 內部函數以 _ 開頭
這是一個範例類別。在這裡,run 方法使用了其他方法 clean 和 transform
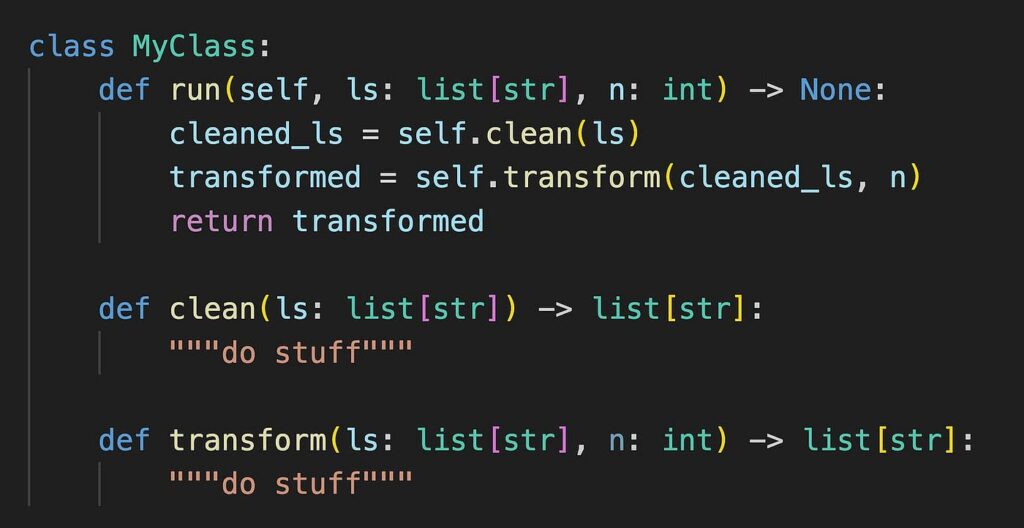
在生產級代碼中,我們力求盡可能明確,因此嘗試區分內部方法和外部方法。
- 外部方法——供其他類別和物件使用的方法
- 內部方法 — 供類別本身使用的方法
按照慣例,內部方法最好以下劃線 _ 開頭
如果我們要重寫上述代碼,我們會得到:
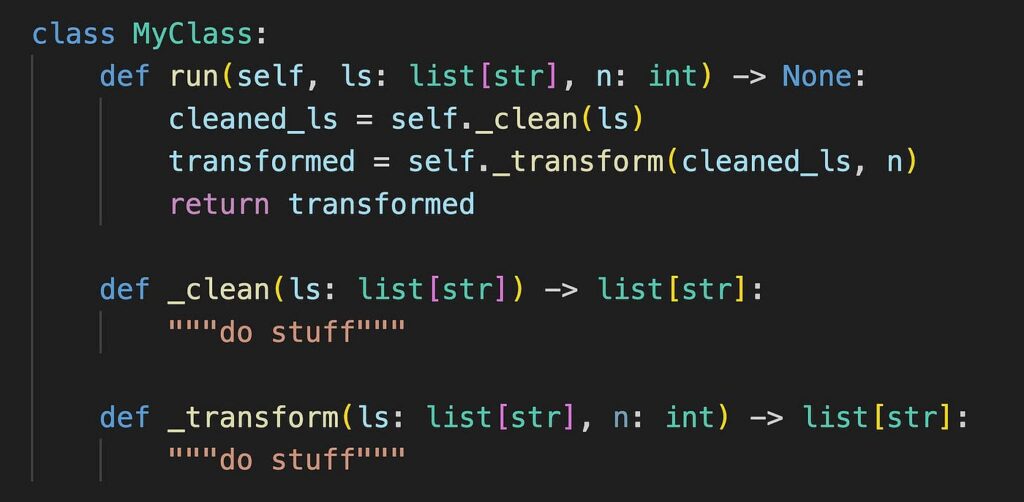
注意 — 在方法名稱前加上底線並不會隱藏它使其對其他類別和物件不可見。事實上,在功能上沒有任何區別。
12) 用於常見功能的裝飾器
這是一個包含 3 個函式的類別,每個函式執行不同的操作。然而,請注意,不同函式之間存在相似的步驟——try-except 區塊以及日誌功能。
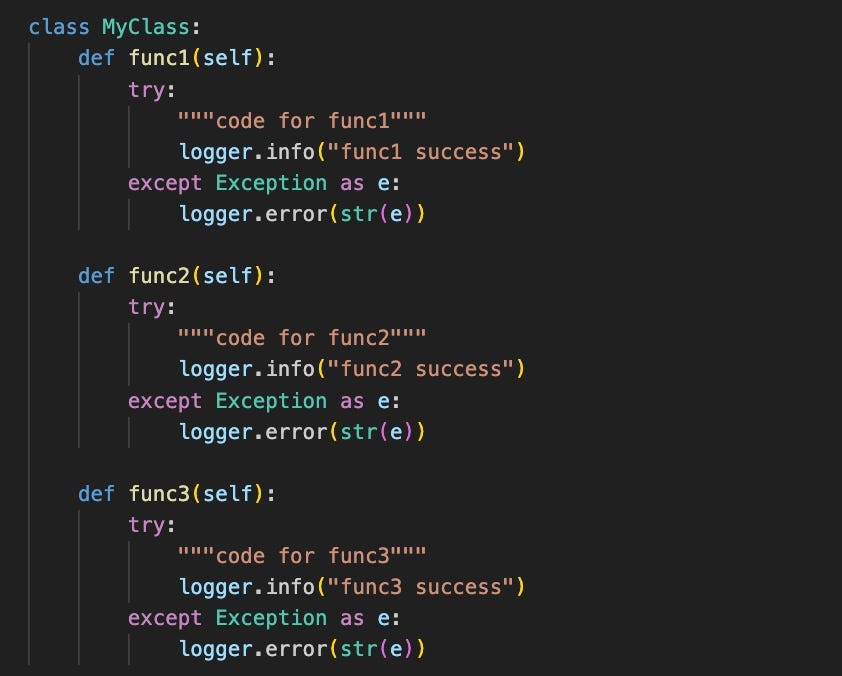
減少重複程式碼的一個好方法是撰寫一個包含共同功能的裝飾器函數。
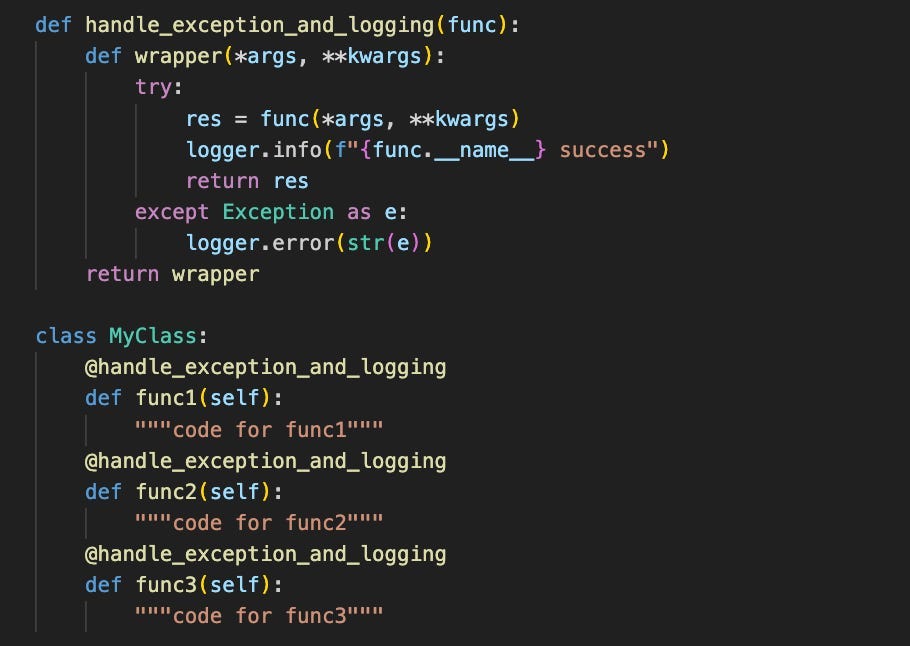
這樣一來,如果我們想要更新共用程式碼(try-except 和 logging 程式碼),我們不再需要在三個地方進行更新——我們只需要更新包含共用功能的裝飾器程式碼。
