大約六個月前,當我加入Blitz時,我們已經將我們的 Elixir 後端遷移到 Rust 的過程中走了一半。我不認為 Elixir 作為一種語言有任何問題,但其實現方式並不是最高效的,並且它的成本相當高。無論如何,遷移背後的思路是,用 Rust 重寫將會顯著更快且更便宜。所以我首先問自己的問題就是這篇文章標題所提到的。Rust 到底有多快?嗯,從我的測試中得知,它確實非常快。
告白
讓我們暫停一下,來個誠實的開發者告白時間:我從未在專業領域中使用過 Rust 或 Elixir。我的後端履歷讀起來就像 Stack Overflow 的「熱門語言」部分——Java、Python、Go、JavaScript/TypeScript、PHP、C#——但不知何故,我成功地避開了這兩種特別受歡迎的技術。
Rust 繼續被譽為最受推崇的程式語言,去年獲得了 83%的高分,而我也做了典型的開發者會做的事——在午餐時以 1.5 倍速觀看 Fireship 和 Prime 的 Rust 教學影片。你知道的,就是那種「我總有一天該好好學學這個」的研究。至於 Elixir?嗯,我只能說,如果沒有 ChatGPT 充當我的個人翻譯,我根本看不懂 Elixir 的程式碼。「這個|>符號是在幹嘛?是打錯字還是語法的一部分?」🤔
但這正是 Blitz 這次遷移之旅如此迷人的原因。在過渡中期加入,讓我得以近距離見證前後效果,而不帶有建立原始系統的偏見。這就像在翻新過程中搬進一間房子——你能看到「之前」的照片和驚人的揭幕,同時避開大部分的施工灰塵。
設定
讓我們面對現實吧——網路上的基準測試就像健身前後對比照:完美得令人懷疑,而且常常缺少關鍵的背景資訊。那些「Rust 快 100 倍!」的標題並不能說服我,我敢打賭你也同樣持懷疑態度。這就是為什麼我不僅分享結果,還要給你完整的配方,讓你可以自己動手做測試。
完整原始碼已在 GitHub 上提供,我真誠地希望你能嘗試證明我是錯的!發現錯誤了嗎?認為你最喜歡的語言應該出現在比較中嗎?請給我發送 PR 或創建一個 issue。如果我早茶後心情特別好,我甚至可能會合併它。
但在我們深入探討那些讓我的 CPU 和腦袋都轉不停的數字之前,讓我先解釋一下我為這些基準測試設定的基本規則:
- 不允許執行緒或平行處理。抱歉了,Go 的粉絲們——這裡沒有 goroutines!這是一場純粹的單執行緒對決,旨在測量無並行技巧下的原始語言性能。
- 極簡的函式庫,最大化的裸機計算。 我們正在測試語言,而非套件生態系統。程式碼盡可能地堅持使用標準函式庫,以保持比較的公平性。
- 記憶體密集型但無需 I/O 操作。 這項測試著重於記憶體存取模式,但避免磁碟或網路 I/O。我們測量的是處理能力,而不是語言在等待硬碟時能多好地閒置。
- 垃圾回收的考量。 這個測試旨在避免語言可能花費一半時間清理記憶體而非進行實際工作的情況。沒有人想看我們來看拳擊賽時,卻在看清潔工打掃。
將這些基準測試視為程式語言中的受控實驗室實驗——或許是人為的,但揭示了影響現實世界性能的基本特徵。歡迎在你的電腦上試試看。
基準
讓我帶你走過我完全業餘的基準測試冒險。首先——我用 Python 寫了最初的基準測試,這仍然是我的編程舒適區,儘管它的聲譽是比在糖漿中游泳的樹懶還要慢。
是的,我確實用 ChatGPT 來潤飾我的程式碼。如果你因此評判我,那我只能假設你還在用手攪拌奶油,並且拒絕使用計算機。各位,現在是 2025 年了——善用可用的工具吧!我對「純粹編碼」的自負在我凌晨兩點的第三次除錯會議中煙消雲散了。
那麼這個基準測試到底做了什麼呢?它非常簡單:
- 生成隨機的 8 字符字符串(10,000 個!)
- 將它們塞進字典/哈希映射/無論你的語言怎麼稱呼它
- 檢查我們是否意外地多次創建了相同的字串(你好,生日悖論!)
- 沖洗並重複三次
- 計算平均運行時間
這個基準的美妙之處在於它觸及了編程任務的甜蜜點:字串操作、記憶體分配、字典/哈希操作,以及一點隨機性——同時避免了 I/O 操作或執行緒的棘手複雜性。
我隨後開始了相當於「程式碼的 Google 翻譯」的語言轉換工作,將這個基準轉換成多種語言,包括神秘的 Elixir(對我來說仍然像外星象形文字)和備受矚目的 Rust。結果如何?只能說它們並不算是驚天動地。如果你在科技界待過超過一週,你可能已經猜到了哪些語言在性能光譜上落在哪個位置——也許有一兩個令人驚訝的例外。
將這視為較少「嚴謹的學術研究」,而更多是「有時間的開發者出於好奇」。但有時正是這些實驗教會我們最有趣的教訓。
結果
好的,鼓聲請準備!經過了這麼多的準備,讓我們來深入探討那些精彩的性能數據。我原本懷著宏大的願景,想要為這篇部落格文章創造出美麗、專業的圖表。然後我記起自己是一名開發者,不是設計師,而我的藝術能力頂多就是 ASCII 藝術。所以,我做了任何一位在 2025 年理性的工程師會做的事——我把它外包給了 ChatGPT。這 AI 可能贏不了任何設計獎,但至少它不會像我的設計師朋友那樣,對我糟糕的顏色搭配指指點點。
原始性能結果
我也把它上傳到這裡的儲存庫了。
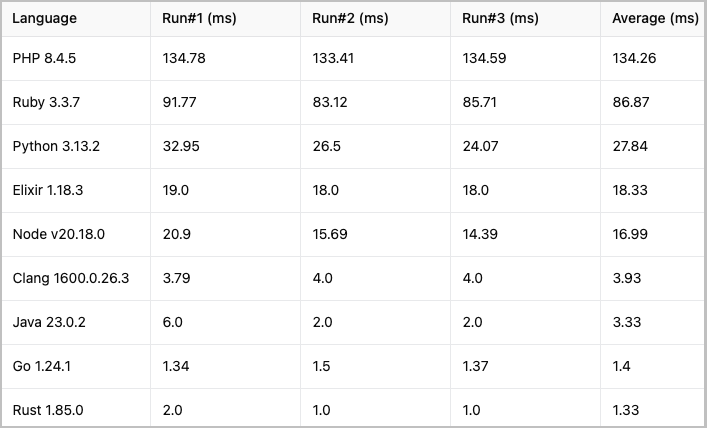
這是一張給視覺型人的圖表:
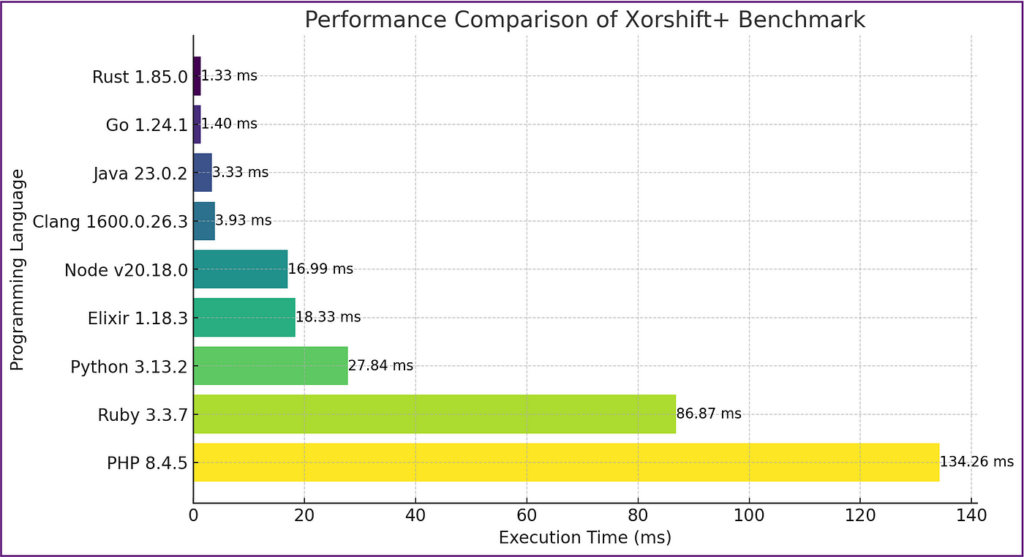
讓我帶你了解這些數字所揭示的內容:
解釋型語言:PHP、Ruby 和 Python 就像是老友重逢一樣,彼此之間相處融洽,但也不刻意搶風頭。它們的表現…正如你所預期的解釋型語言那樣。它們雖然在速度上不佔優勢,但卻是可靠的工作馬,能夠完成任務,只是比編譯型語言消耗更多的 CPU 資源。
編譯型重量級選手:Rust 和 Go 絕對大放異彩。我們說的是「讓其他語言開始懷疑人生」的性能水平。Rust 略勝 Go 一籌,再次證明了它作為速度狂魔的聲譽。我並不驚訝 Microsoft 為 TypeScript 選擇了 Go,但為什麼不是 Rust 呢?也許他們不喜歡開發者在編譯時花那麼多時間喝咖啡 😁
意外的發現:有兩種語言出乎意料。Java 的表現遠超我預期——顯然,自從我上次關注以來,JVM 已經進行了大幅度的優化。另一方面,Elixir 的速度比我預期的要慢,我懷疑是否在這方面做錯了什麼,希望有 Elixir 專家能幫我解答,但等等,他們在哪裡呢?
對數比例:因為有些語言就是快那麼多
如上所見,我將所有數據繪製在線性尺度上,但性能差距如此顯著,以至於有些語言在圖表上幾乎看不出來。這就像比較噴射機與自行車的速度——技術上它們都是交通工具,但這種比較並不十分公平。
僅僅為了樂趣,我切換到了對數刻度,這讓我們能更直觀地看到相對性能差異。即使在這個刻度上,解釋型語言和編譯型語言之間的鴻溝依然顯著。
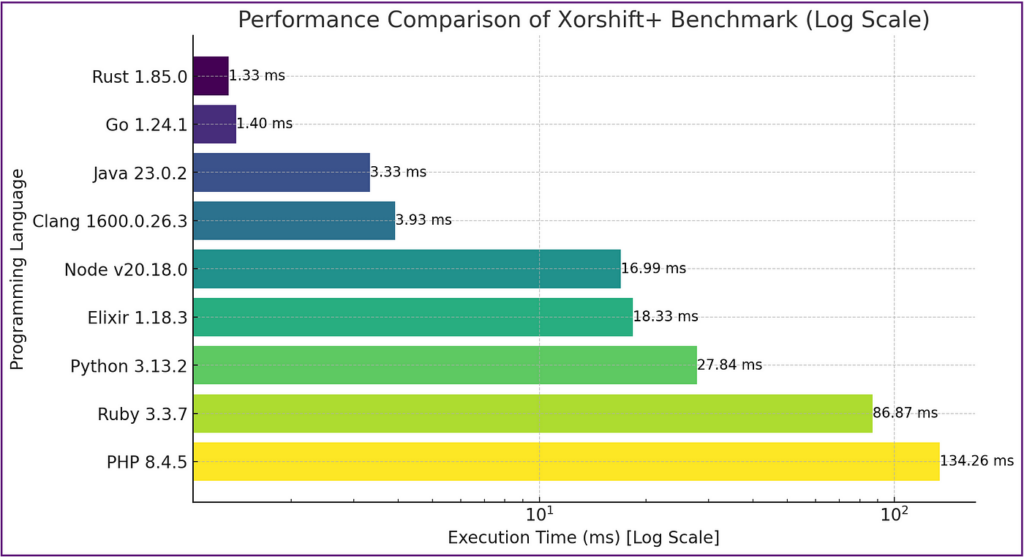
這實際上意味著什麼
令我著迷的不僅僅是哪種語言「勝出」,而是差異的幅度。我們談論的不是邊際收益——我們看到的是可能從根本上改變你如何架構解決方案或你能用相同硬體實現什麼的性能提升。
當 Rust 處理某件事的速度比 Python 快 20 到 30 倍時,這不僅僅是一個技術上的註腳——這意味著需要 20 台伺服器與僅需一台的區別。或者是在 300 毫秒與 10 毫秒內處理一個請求的差異。在規模上,這些差異不僅重要——它們成為了決定性的優勢。
話雖如此,開發速度、生態系統的豐富性以及團隊的熟悉度仍然非常重要。但如果原始處理能力是你夜不能寐的原因,我認為這些數字已經不言自明。Rust 以速度著稱並非只是行銷噱頭。
我對你的想法很感興趣,請在下方留言告訴我,如果你對更多業餘基準測試感興趣,你可能會對我下面的 Rust vs Go 文章感興趣。
