本文旨在了解 EDA、其在數據科學中的作用,並掌握統計分析、特徵選擇和可視化的關鍵技術。EDA 是數據分析的關鍵步驟。一旦收集了數據,下一步是清理和準備數據,並在進行複雜分析之前確定其有效性。因此,EDA 是數據分析的第一個也是最關鍵的步驟。它幫助我們
- 了解數據集的結構和特徵。
- 偵測遺漏值、離群值和異常值。
- 識別模式、關係和分佈。
- 決定機器學習模型的特徵選擇和工程化。
了解您的數據
資料分析的第一步是了解您的資料。讓我們從載入我們的資料集並檢查其資料結構開始。 就本文而言,我將使用 PyCharm,我的資料集是來自 Kaggle 的 Titanic 資料集 — https://www.kaggle.com/datasets/yasserh/titanic-dataset
import pandas as pd
df = pd.read_csv("Titanic-Dataset.csv")請注意,我正在處理的 CSV 檔案位於專案資料夾中。如果您的檔案位於其他位置,請輸入完整的檔案路徑。一旦我們載入了資料集,讓我們將其列印出來,以確認是否已正確載入。
print(df.head())我正在使用 head()來只列印數據集的前 5 行,從中我可以檢查數據集是否已正確載入以及我的數據集中有什麼類型的列。
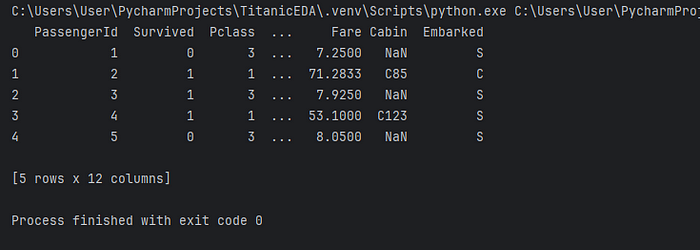
查看欄位詳情
print(df.info())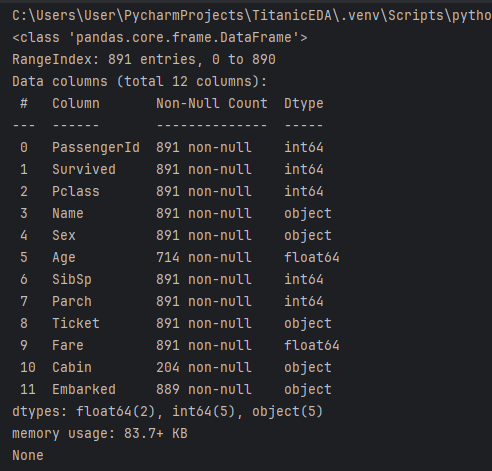
我們可以看到欄位、它們的資料類型以及每個欄位有多少非空值。例如,在上述資料集中,共有 891 筆資料,但艙位欄位只有 204 筆資料。作為分析師,您可以決定是否考慮這些資料。Pandas 有另一個函數叫做 describe()非常有用,可以一目了然地獲得資料的更廣泛概念。
print(df.describe())您可以查看每一列的計數、平均值、標準差、最小值和最大值等。一旦對數據有基本的了解,下一步就是清理數據集。
數據清洗 — 處理缺失值
早期我們發現該數據集存在缺失值,這是大多數數據集中的常見情況。在本節中,我們將重點關注如何查找和處理缺失數據。
print(df.isnull().sum())
本行為純文字輸入,翻譯至繁體中文。若翻譯不必要(如專有名詞、代碼等),請直接返回原文。 這是找出每個欄位中空白條目總數的最佳方法。這是我們泰坦尼克號數據集的輸出結果。
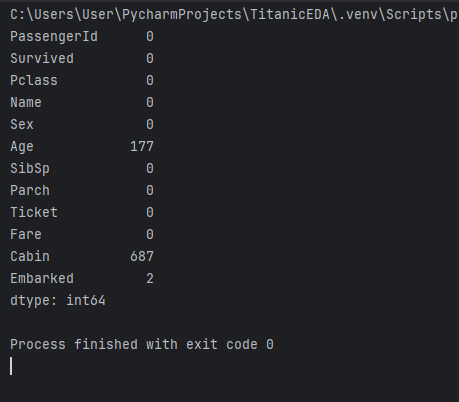
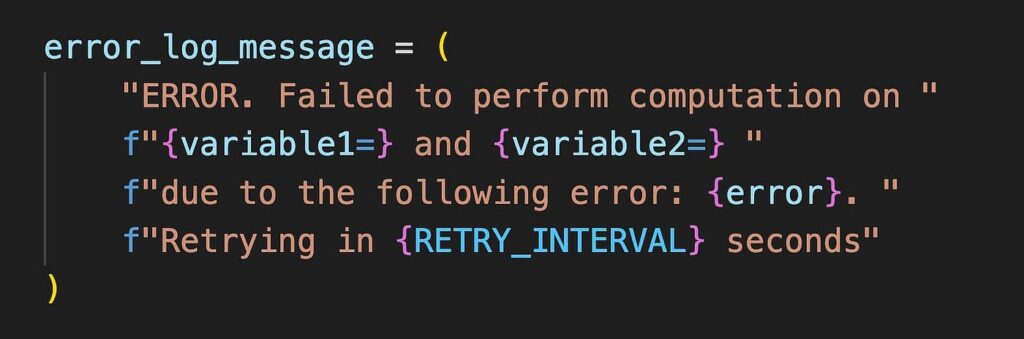
我們可以看到大多數列沒有空值。這並不意味着這些列中的所有數據都有效或有用,這只是意味着這些列沒有空值。但是,Age、Cabin 和 Embarked 列有空值。您可以採取多種方式處理這一問題。如果這種做法會產生小影響,您可以刪除包含空值的行。或者,如果數據很重要,您可以填充空值。例如,在我們的數據集中,如果我們刪除包含 Cabin 列空值的 687 行,我們將只剩下 204 行數據。但如果我們的數據集有 50,000 個條目,也許影響會更小?這完全取決於您的數據集、其大小、我們想要刪除的數據類型以及對我們分析的總體影響。作為數據分析師,這些都是您必須做出的關鍵決策,這些決策最終將決定您的分析是否有效。
為示範目的,讓我們假設我們決定丟棄 Embarked 欄包含空值的值,
df = df.dropna(subset=['Embarked'])
對於另外兩個欄位,我將以預設值填補缺失的值。對於「年齡」這個數值欄位,我將以資料集的平均年齡來填補缺失的值。
df['Age'].fillna(df['Age'].mean(), inplace=True)小屋是一個字母數字列。對此,我將使用預設值”未知”。
df['Cabin'].fillna('Unknown', inplace=True)讓我們再次運行 df.isnull().sum()來查看我們的工作是否成功。
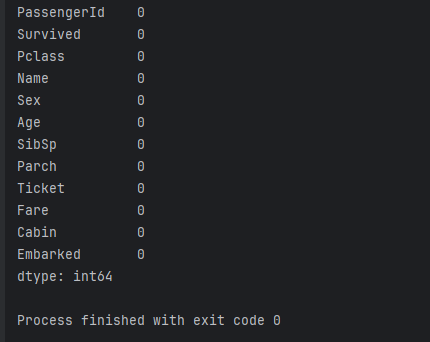
我們的數據集中現在沒有任何遺失的值。
數據清洗 — 檢測和處理異常值
統計學中,異常值是與其他觀察值有顯著差異的數據點。異常值可能由於多種原因而產生,例如新穎數據、測量變異性和實驗錯誤。如果確實是實驗錯誤,則應從分析中刪除該數據。但首先很重要的是確定您的數據集是否存在異常值,然後處理它們。
辨認離群值的一種方法是使用箱形圖。如果您熟悉統計學,使用和解讀箱形圖將很容易。讓我們先建立一個非常簡單的箱形圖。
sns.boxplot(x=df["Survived"])
plt.show()倖存的欄位應該只有兩個值,要不就是 1,要不就是 0。讓我們現在檢查箱型圖吧。
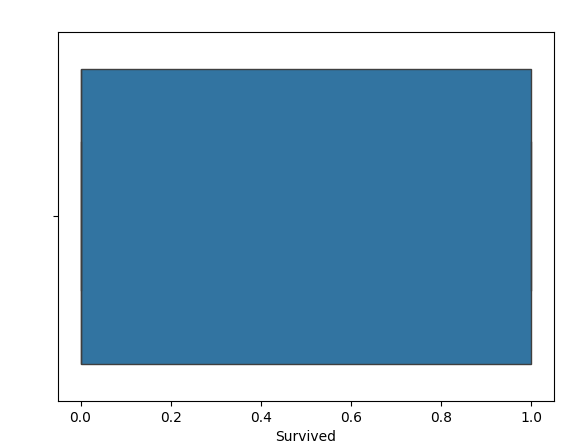
我們從這個圖表可以看出,沒有任何異常值。如果存在異常值,它們會以點的形式表示在盒子外部。以”Fare”列為例,
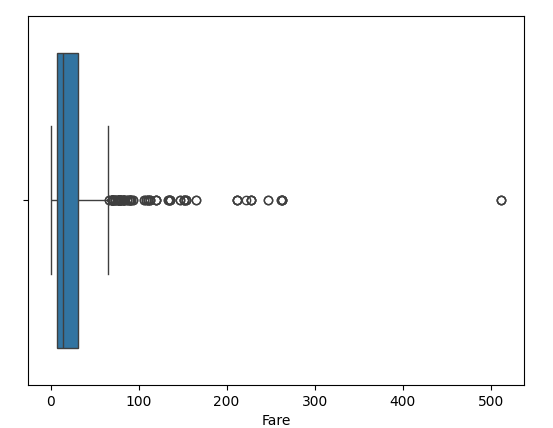
我們可以看到這個圖表中有幾個異常值,也有一個極端異常值。是否保留或移除異常值取決於資料分析師的需求,不應盲目移除異常值,因為它們可能是真實的資料點。一旦確定了異常值並決定是否要移除它們,您可以使用四分位距 (IQR) 來執行該操作。當然,您也可以手動移除它們。
統計學中,四分位距(IQR)被定義為數據第 75 百分位與第 25 百分位之間的差值。
Q1 = df["Fare"].quantile(0.25)
Q3 = df["Fare"].quantile(0.75)
IQR = Q3 - Q1
df_filtered = df[(df["Fare"] >= (Q1 - 1.5 * IQR)) & (df["Fare"] <= (Q3 + 1.5 * IQR))]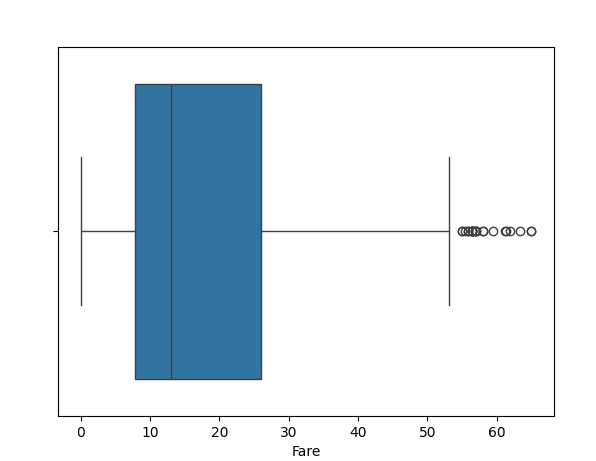
現在箱型圖看起來如何不同。因此,在去除異常值之前,非常重要要先思考這些是實驗錯誤還是真實數據點。
了解數據分佈
除了離群值之外,了解數據分布情況還可以窺探數據如何分佈,這有助於決定轉換、標準化等處理方式。首先,我將使用直方圖來視覺化數據分布。
sns.histplot(df["Fare"], bins=30, kde=True)
plt.show()請注意,我正在使用原始資料框架,未對票價欄應用四分位範圍,因此可以展示更大的分佈。
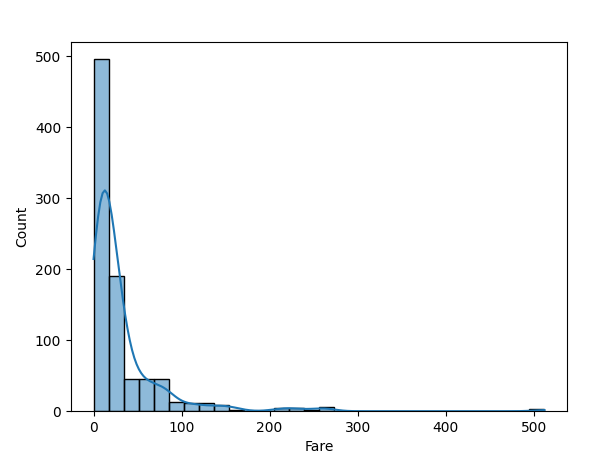
我們可以看到最高數量的記錄位於 0 至 100 之間,並有少數介於 200 至 500 之間的離群值。另一種識別數據分佈的方法是檢查偏斜度。
print(df["Fare"].skew())如果您獲得的值為>1 或<-1,則數據存在偏斜。因此,理想值應介於-1 和 1 之間。我對上述數據集獲得的值為 4.801440211044194。這意味著我的數據集存在偏斜。
請記住我們在應用四分位距後的 df_filtered 資料集?我對該資料集應用了 skew() 函數,得到的值為 1.4306715336945985。該資料集仍然偏斜,但與先前版本相比,已不再極度偏斜。
您可以使用對數轉換來修正偏斜數據。它通過取值的對數來修正偏斜,本質上是壓縮大值並拉伸小值,有助於平衡分佈。現在這完全取決於您正在處理的數據類型,因為它不適用於所有類型的數據。
df["Fare"] = np.log1p(df["Fare"])在運行 df[“Fare”].skew()後,我得到了值 0.40010918935230094,這意味著我們的數據集現在適度歪斜。
特徵關係和相關性
特徵工程是 EDA 的重要組成部分。讓我們先看看數據中的特徵關係和相關性是什麼。數據中的特徵關係是指數據集中不同變量之間的連接或關聯,本質上描述了一個特徵的變化如何影響或與另一個特徵的變化相關。通常使用相關分析等統計方法來衡量變量之間關係的強度和方向。一個基本的例子就是一個包含學習時數和成績的數據集。
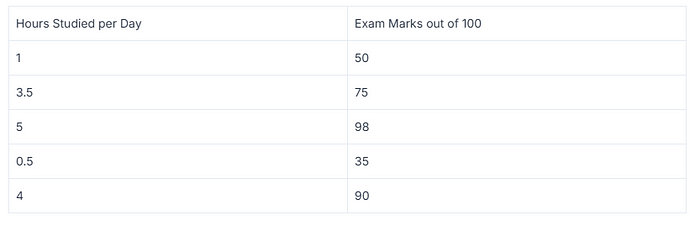
根據我們的數據集,我們可以看到,學生學習的時間越長,在考試中獲得的成績就越高。這意味着學習時間和成績之間存在着關係。這就是我們所說的特徵關係和相關性。
我們可以使用熱圖來識別您數據集中數值之間的相關性。
print(df.corr(numeric_only=True))
sns.heatmap(df.corr(), annot=True, cmap="coolwarm")
plt.show()相關矩陣返回了我們數據集的以下輸出。我在應用任何 IQR 或對數轉換之前使用了該數據集。
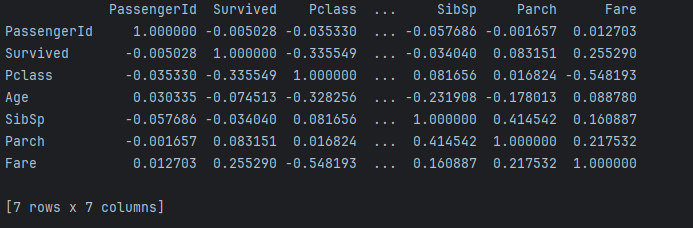
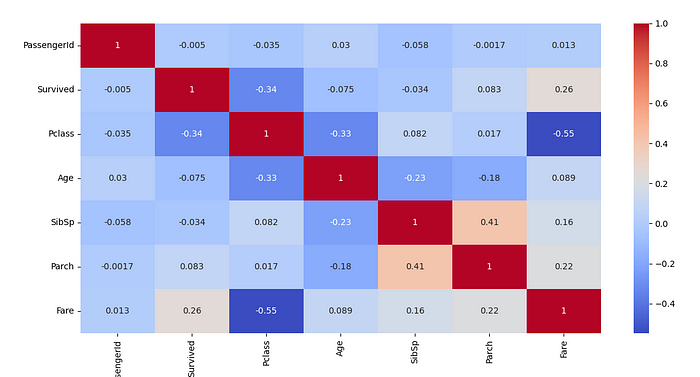
現在讓我們解釋這些結果。相關性的值從-1 到 1。
- 正正正正正
- 負 1 表示完美的負相關(一個增加,另一個減少)
- 0 表示無相關性(特徵是獨立的)
在先前的學生考試成績範例中,我們可以說,學習時數與考試成績呈現正相關,而缺席日數則可能與考試成績呈現負相關。有了這些認知,我們可以嘗試從上述熱圖中,找出資料集中任何變數間的特徵關係。
讓我們進一步嘗試使用散佈圖來理解特徵之間的關係。從上面的熱力圖中我可以確定票價和乘客等級之間存在關係。
sns.scatterplot(x=df["Fare"], y=df["Pclass"])
plt.show()如果您想要檢查多個特徵,則我們可以使用對配圖。
sns.pairplot(df)
plt.show()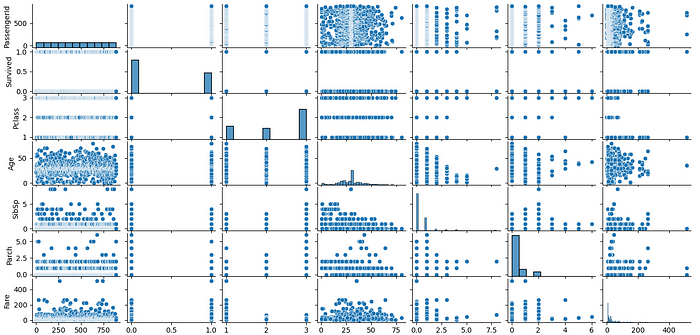
目前為止,我們已經探討了數值特徵之間的關係。現在讓我們來看看類別特徵。由於類別特徵並非數值型,因此我們需要以不同的方式分析它們。我們可以如下統計類別特徵的唯一值數量:
print(df["Cabin"].value_counts())這將告訴我們船上的獨特艙房名稱。
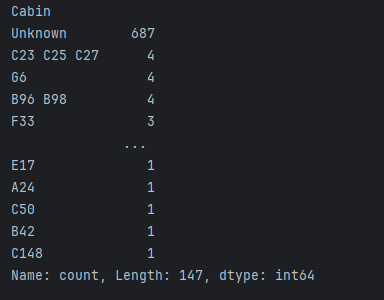
正如我們之前討論過的,我們通常使用條形圖來可視化類別數據。讓我們看看有多少男性和多少女性登上了這艘船。
sns.countplot(x=df["Sex"])
plt.show()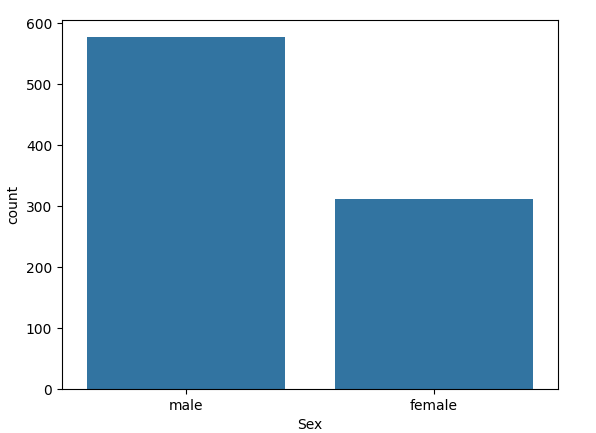
乍看之下,我們可以看到船上乘客中男性比女性多。
如果我們想探索更多,我們可以進一步了解機器學習中的 Python 庫,如 sklearn,學習特徵選擇和工程。我們可以選擇最重要的特徵進行分析,將分類變量轉換為數值以用於機器學習模型。我打算到此結束本文,希望能夠撰寫更多關於使用 Python 進行數據分析的文章,重點關注更高級的 Python 庫和機器學習技術。